データ収集からAIモデル評価まで 高品質な教師データでAI開発を支援
AppenはAI市場の平均よりも3倍速いスピードで教師データの提供が可能です。データ収集からアノテーション、トレーニング、モデル評価などAIや機械学習プロジェクトのあらゆるフェーズに対応したソリューションを提供しています。
お問い合わせ
AppenがサポートするAIモデル
Appenは、以下のような機械学習モデルを開発するために必要な、高品質で偏りのない教師データの作成、アノテーション、モデル評価などのサービスを行っています。

データ収集

データ準備&アノテーション

モデル評価
ユーザーテストと競合他社に対するパフォーマンスのベンチマークを行い、潜在的なパフォーマンスギャップを特定し、パフォーマンスの最適化に必要なデータを準備します。

広告評価
コンテンツとランディングページが、検索、コンテンツの内容、文化、ターゲットのニーズと関連していることを確認し、質の高い結果を提供します。

サイトコンテンツ評価

サイドバイサイド評価
ブラインドテストでより良い結果が得られることを確認した後、自信を持ってモデルのアップデートを行い、パフォーマンスを最適化して成功に導きます。
カタログ・タクソノミーの開発
顧客の検索ワードとタグを一致させ、コンテンツ推薦を向上させます。
カテゴリー分類
様々なデータの種類に対応
画像、動画、音声、テキスト、マルチメディアなど、あらゆる種類のデータをサポートします。
SNSの投稿監視
ニュースフィードとソーシャルメディアの評価により、コンテンツの信憑性を確認します。
検索結果の関連性
ジオ・ローカル評価
マップ検証
実態評価と情報の訂正

優れた拡張性
信頼性の高い学習データ
ローカライズ
現地の専門家を独占的に起用し、オプションで複数の連動した地域を指定できるため、ターゲット市場に合致したデータを確保できます。

コンピュータビジョンとパターン認識
お客様の要件に特化した豊富なデータセットにアクセスし、実世界のシナリオに適切に対応できるよう、適切な情報を用いてモデルを十分にトレーニングします。
発話データ収集
235以上の言語と方言のヒューマンアノテーション付き音声データを使って、最高の自然言語処理、理解、自動音声認識ソリューションを構築します。

自動音声認識
大量の高品質言語データ(録音、転写、アノテーション、ローカライズ)にアクセスし、モデルが複数の言語、方言、環境、文脈における人間の音声を正確に理解し応答できるようにします。

対話コーパスの収集
主要言語・方言に対応した多言語テキストデータ収集サービスを提供します。

AIチャットボット
動画アノテーション
効率的なアノテーション
モデルライブラリから最適なモデルを選択することで、アノテーションプロセスを高速化します。出力結果をクラウドワーカーに送信し、必要に応じてレビューや編集を行うことができます。
画像文字起こし
画像中のテキストを囲むバウンディングボックスを描画し、同じステップで自動転写を行うことができます。より堅牢なOCR学習データのために、ローカライズされたテキストを取得します。
画像アノテーション
セマンティックセグメンテーション
コンピュータビジョンモデルのために、画像にピクセル単位でラベリングを行います。PLSSを使用して、ピクセルレベルまで非常に正確にラベリングし、精度とパフォーマンスを向上させます。

3D点群データアノテーション

テキストデータの収集
私たちは、すべての主要な言語と方言で多言語テキストデータ収集サービスを提供しています。当社のテキスト発話収集およびテキスト生成サービスは、高品質のカスタマイズされたテキスト発話を大量に収集したり、チャットボットや会話型AIモデルがあらゆる会話シナリオに対応できるよう、シナリオベースのレスポンスを生成することができます
テキストアノテーション(固有表現抽出 - NER、品詞タグ付け - POS)
名前付きエンティティや品詞を関係づけてNLPラベリングを拡張し、モデルがテキストコンテンツの関連性を形成し、より深く理解できるようにします。
固有表現抽出
関連するエンティティをハイライトして分類し、大量のテキストから重要な情報を導き出すためにモデルをトレーニングして、モデルの認知能力を向上させることができます。

感情・インテント分析
顧客からの問い合わせの背後にある意図を理解し、顧客とのやり取りからインサイトを得ることで、有意義な会話をする機会を増やすことができます。

検索結果評価
このデータを使って、お客様の検索に最も関連性の高い検索結果を返すモデルをトレーニングすることにより、検索結果をランク付けし、ユーザーエクスペリエンスを向上させます。

翻訳品質の評価
音声収録
音声認識によるバーチャルアシスタント、音声検索機能、Voice to Text機能などのトレーニング用に、高品質でカスタマイズされた音声データを大量に収集します。 データ収集をスタンドアロンサービスまたはマルチコンポーネント成果物の一部として提供します。

オントロジーデザイン
アプリケーションが理解する必要のある項目やイベントを整理し、テキスト情報と項目プロパティの関係を容易にするオントロジーを作成します。

対話デザイン
アプリケーションの機能に基づいてユーザーシナリオを作成し、ユーザーの問い合わせに簡単かつ正確に回答できるようにチャットボットを訓練します。

データアノテーション

モデル評価
モデルの成功を測定し、軌道修正が必要な部分を特定し、設計と性能の改良をサポートします。
多言語データセット

データ作成とデータ収集

物体検知と認識
デジタル・オブジェクトを物理的なオブジェクトに重ね合わせ、相互作用を媒介します。

物体ラベリング
画像やシーン構成要素に説明用のラベルを表示します。
音声認識
発話されたキーワードにマッチした画像エフェクトをトリガーします。

テキスト認識と翻訳
書籍や道路標識などの文字に翻訳を重ねて表示します。

プロシージャルコンテンツの生成
バーチャルヒューマン

インタラクションシステム
音声アノテーション
音声認識やその他のオーディオモデル用に、音声をレイヤー、スピーカー、タイムスタンプに分割し、異なるスピーカーやその他のオーディオキューを正確に識別できるようにモデルをトレーニングします。
音声文字起こし
内蔵のNLPモデルを活用して、トランスクリプションの品質と効率を改善し、話し言葉をテキストに書き起こしたり、機械で生成したトランスクリプションを検証して音声音声認識モデルを正確に学習させます。
音声分類

プロジェクトの構造
プロジェクトのための綿密で構造化された基盤、および品質保証のためのテーラーメイドのプランの作成を支援します。

スクリプトの専門家

コミュニケーション

迅速な課題解決

プロジェクトマネジメント
日常的なプロジェクトマネジメントと人事機能を担う

品質保証
翻訳メモリ

用語集

翻訳の一貫性チェック
ステップ1:データ収集
データ収集
画像収集
ラベリング済ソリューション

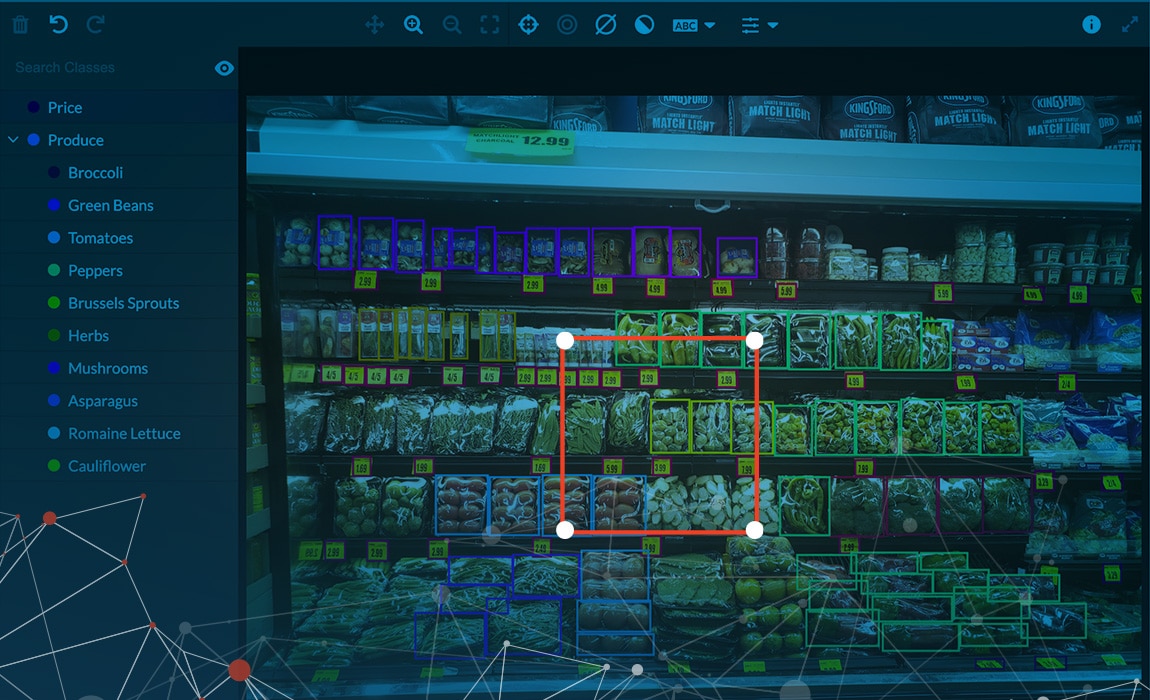
機械学習、パターン認識、コンピュータビジョンソリューションのためのデータ収集能力を向上させることができます。詳細な仕様に焦点を当て、参加者の属性、背景画像、環境要因などをカバーし、お客様のプラットフォームのための真のデータ収集の多様性を確保します。
独自の差別化ポイントとして、iOS/Android用の画像・動画データ収集モバイルアプリを独自に構築し、品質保証とアノテーションのためのオンラインプラットフォームも開発しました。 これらの独自ツールにより、複数のコレクションのデータ収集をより迅速に拡張し、真にグローバルなカバレッジを実現することができます。

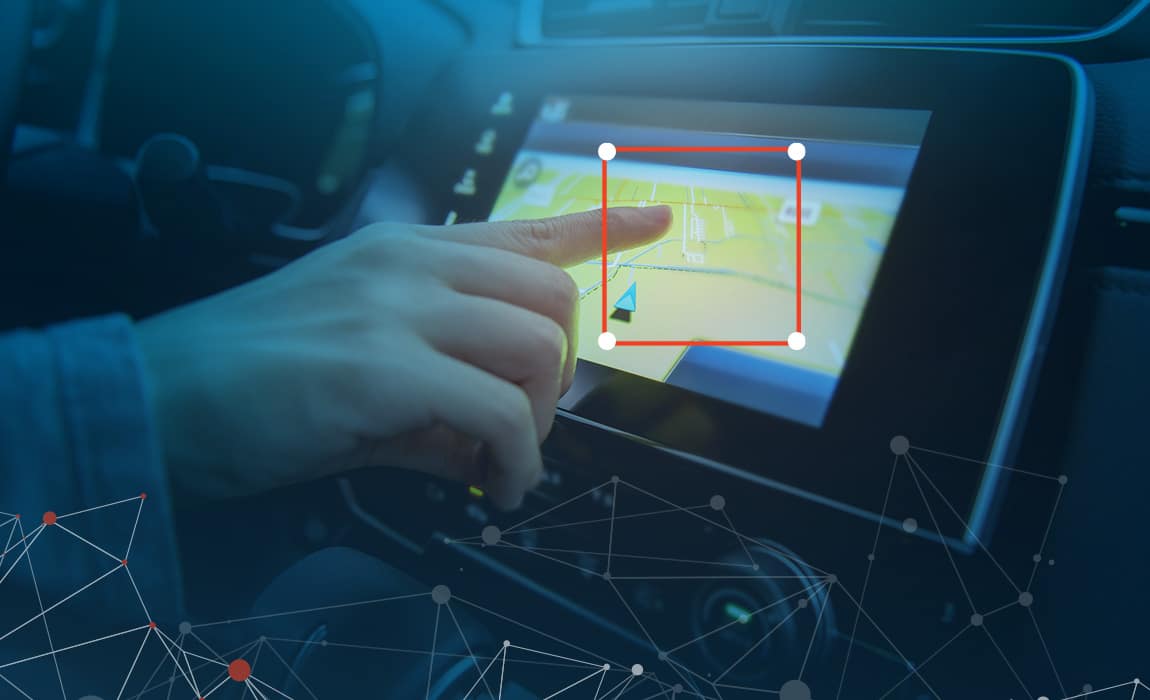
当社独自の POI データ収集および検証プラットフォームを活用し、オーダーメイドで正確かつ完全な POI データセットを取得します。Geolancer は、お客様の特定のビジネス要件に合わせた、あらゆるカスタム属性を持つ POI データセットをオンデマンドで構築できる唯一のプラットフォームです。100 万人以上の貢献者からなるグローバルネットワークは 170 カ国以上をカバーし、Geolancer を活用してあらゆる規模の POI データを収集することが可能です。

ステップ2:データ準備
概要
アノテート
翻訳

概要

分類
あらゆる種類のデータを、当社のプラットフォームを使って大規模に分類・区分けすることができます。
大量のコンテンツを正確に分類します。
データタイプ:
画像

動画

音声

テキスト

3Dセンサ


アノテーション
データタイプ:
画像
動画
音声
テキスト
3Dセンサ

文字起こし
文書、テキストを含む画像、Webサイトの情報を文字に書き起こします。自然言語処理(NLP)や音声認識(ASR)プログラムの拡張に対応した書き起こしサービスです。
内蔵のNLPモデルは、書き起こしの品質と効率を向上させ、話し言葉の音声をテキストに書き起こしたり、機械で生成された書き起こしを検証したりすることができます。
データタイプ:
画像
動画
音声

翻訳
データタイプ:
動画
音声
テキスト
ステップ3:モデルトレーニングと展開

ステップ4 人手によるモデル評価

セキュアなデータ
お客様の機密情報を保護するエンタープライズレベルのセキュリティ

セキュアなデータアクセス
個人を特定できる情報(PII)や保護されるべき医療情報(PHI)を扱うお客様や、その他の高度なコンプライアンスニーズに対応したデータセキュリティの要件を満たしています。

セキュアなクラウドワーカー
お客様のビジネスニーズに合わせて、安全な施設、安全なリモートワーカー、オンサイトサービスを通じてデータ保護を確実にする柔軟なオプションを提供しています。

セキュアなファシリティ
個人識別情報(PII)やその他の機密データを扱うプロジェクトをサポートするために、複数の地域に拠点を持ち、政府レベルの認証に至るまで、さまざまなセキュリティレベルに対応した適切な人材、ポリシー、プロセスを備えています。

セキュアなワークスペース
ISO27001認証取得のリモートセキュアワークスペースソリューションにより、当社のグローバルクラウドが、物理的なセキュリティ施設にアクセスすることなく、お客様の機密プロジェクトにリモートで作業することができます。これにより、遠隔地のクラウドの多様性が偏りを減らし、世界的な混乱があっても多言語をサポートすることができます。

認定
私たちは、データプライバシーとセキュリティに準拠し、すべての主要な認定および認証を取得しています。




